Things are not simple when it comes to Software Eco-Design.
Eco-Design is about maximizing a software Efficiency function of Usage, which can be defined as a ratio :
Efficiency(U) = Utility(U) / Resources(U) (U = Usage, a parameter)
- Utility is related to the amount of useful work you can do in a unit of time (the word useful is important, because it depends on the context and what you need to achieve).
- Resources, for software is the amount of computation, data, I/O you use, which in turn, corresponds to an amount of energy (electricity) and hardware resources (servers, routers, wires, satellites, laptops, smartphones, …). The more software resources your application use, the more energy you will need, and the more powerful hardware you will use.
- Usage (U), corresponds of how your software is used. Usage is about how often your users will connect to the app, how many, from which county, etc. It is a parameter of Efficiency, Utility, and Resources because software impacts heavily depend on how the users will use it. The same software used differently may use up different amount of resources or have different utilities. Most importantly, Efficiency, Utility, and Resources might not be a linear function. Think of Amazon for instance: the utility might vary largely depending on the number of users, and the resources on where those users are located on the planet.
- Energy and hardware resources end up to be direct impacts on the planet, contributing to climate change or environment destruction (side note: the IT sector is expected to reach 10% of GES within 5 years, that is to say the equivalent of all personal vehicles worldwide).
As you can guess, you can either consume less resources, but also, you can get better at utility for improving efficiency, the best case scenario being able to do both at the same time (increase utility while consuming less resources).
As an illustration of utility, when developing a data science application, you would probably be better off using Python over C++, although C++ is a much more energy-efficient programming language (see here for the details). Although Python is very energy consuming, it is more useful than C++ when it comes to data science, because it brings many data-oriented APIs that leverage decades of data-science and machine-learning research.
In other words, you have to use the right tool for the right purpose: do not use a screw driver if you have to nail.
Unfortunately, software engineering is full of contradictions and is not always intuitive. What is true for a given usage might not be true for another one, and that’s why benchmarks can be misleading. More importantly, after years of practice, software engineers all know that it is not possible to win it all. Typically, if you win in speed (computational complexity), you most of the time loose in memory consumption (which also means scalability). For instance, take a look at the Sieve of Eratosthenes, one of the most calculation-efficient way to find the prime numbers. It requires to allocate a big table and thus uses up a lot of memory. What you get on one side (CPU) is lost on the other side (Memory). Both CPU and memory will have impacts on the natural resources that will be required by your application… So you will have to chose the best algorithm for your usage.
The CAP theorem is a fundamental theorem in Computer Science that formalises and proves this harsh reality: you can only get 2 out of the 3 desired properties for a piece of software using data (i.e. all real-life software):
- Consistency: the data is the same for every one.
- Availability: the data (and service) is immediately available (no wait period).
- Partitioning: the data can be partitioned (partition tolerance), that is to say, the data can scale to as many users/nodes you need it to scale.
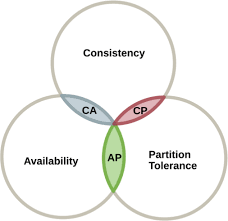
As an illustration of the CAP theorem, think about a Remote File System and how the client application can cache the files from that FS. By caching the files, you get better availability (the application is faster without having to download any files and will save networking resources). But you get less consistency, since you might loose updates of that files. You may get some consistency back by implementing a push protocol… but then you loose some scalability, and so on…
So, in the end, the important is not to optimize to get the most performant software… the important is to know what points you are ready to give up to get what you actually need.
Trying to get the best and most efficient software for all cases has been proven to be impossible by the CAP theorem. So you have to compromise, and in order to do so, you absolutely need to talk to your users, know their actual needs, and be ready to adapt. At some point (if possible early in the project), your users will have to understand that having it all is not possible and you should help them to prioritize.
You have to use the right tools for the right purpose. Let’s say you need scalability, you may use HADOOP, which is a Java Map/Reduce API developed by Apache over HDFS (a distributed file system) to take care of big data computations. However, in 2014, Adam Drake showed that simple CLI script can perform 235 times faster than HADOOP, if you don’t need scalability.
Before you start using a new framework, library, application, or even a new language, you need the following.
- A clear understanding of the data lifecycle and of the Consistency, Availability and Partitioning expected by your users (CAP theorem).
- How the users will use it (expected visits/request statistics).
- How the library/language/framework behave and what they consume in the kind of usage you have identified (make sure you use the most appropriate).
- Create a UX and a technical design which respond to the needs of the users with as little as possible resources used (that’s the principle of eco-design).
To help you with all these, you can take the following actions.
- During the requirements and design phases, simulate the impacts of a design for a given usage. You can simply use an Excel sheet to see how the expected traffic will impact the data and CPU. There are plenty of sources on the Internet where impacts of hardware are quantified and you can use it as input for your simulations.
- Imply your users in the design process by iterating together on the simulated impacts and discussing different scenarios.
- During all the phases, use green patterns, good practices and recommendations. However, challenge each of them against your context. You have to understand the impacts of a design decision. For instance, implementing a local-first approach or using CQRS (Command Query Responsability Segragation) will have great impacts that you need to understand and quantify.
- During the development and maintenance phases, measure how much the final software consumes in order to improve your understanding and take further actions to optimise its efficiency.
Conclusions
Software engineering and software development are very complex activities. If you add eco-design to it, it adds complexity and requires a deeper understanding of your decisions and design choices, as well as quantified inputs to evaluate your impacts.
When it comes to eco-design, the more experienced developers and architects will generally make better decisions, because they have a wider knowledge and will be able to pick up the right tool/pattern from a wider set of possible choices. You should avoid making the default choices (choices based on hype or just because everyone else do it). You will need developers and architects that truly understand why they make a decision and explain it well, with quantified impacts simulated (not just the Github number of stars metrics ;)).
Get ready to investigate the impacts of monoliths v.s. micro-services, local-first, CQRS, REST vs GraphQL, Elastic Search replicas, etc.
Want to know more? Contact me at info@cincheo.com