In this post, I explain the dLite low-code platform approach to build frontend applications. dLite relies on a new paradigm called the Local-First Software paradigm. With this paradigm, one can build applications using local data, which remains the ownership of the user. A generic synchronisation protocol is used to access the data cross-device, and a sharing protocol is used to share data among users and build collaborative applications. I explain that the Local-First paradigm is particularly well-fitted to low-code, since it removes the need of a specific backend and database for each application. Additionally, security and data privacy comes by design, so that all the complex access-right management usually required on the server-side for collaborative applications is not required anymore. As a consequence, it drastically reduces the complexity of the application as well as its maintenance and evolution costs. Last but not least, it is Green IT friendly since it opens the door to a better use of resources by reducing remote invocations, taking better advantage of the terminal (client) side computing power, and saving complex server-side CI/CD, application-server layers, and huge centralized databases.
Introduction
In the recent years, Low Code has been gaining traction. More and more big actors are deciding to trust low-code operators to implement various types of software, such as data and API connectors, workflow orchestrators, and frontend software.
This trend can be easily explained. First, software has been industrializing to scale and provide more quality. The CI/CD allows micro-services-based software to be tested and deployed continuously to ensure better quality and less bugs. However, mastering the software factory art requires skilled developers and architects (and devops). These kinds of experts can be difficult to find and too expensive for small businesses. Second, technology has been evolving very fast, which means that it is becoming difficult and expensive to anticipate the future and make the best technical choices. For instance, the container orchestration technical choices for setting up a micro-service stack can rapidly become cumbersome. Also, because the Web frontend frameworks are changing all the time, it is almost impossible to rely on a long-term lasting development environment. Additionally, most good developers are sensible to hype-oriented buzz, and it is difficult to keep them motivated when not using state-of-the-art technologies.
As a consequence, most industrials are looking at low-code solutions, since the promises are attractive. Promise 1: with low-code, you do not directly depend on development frameworks anymore. You can let the low-code operator deal with the technical aspects of the software factory and keep the software up-to-date with the always-changing technologies. Promise 2: with low-code, you can also take advantage of less techno-oriented people, so-called “citizen developers”. Functional people will be able to leverage low-code tools to structure so-called “shadow IT” and set up new applications and services without needed a scrum team of skilled developers and a complex CI/CD pipeline to be deployed.
Unfortunately, low-code promises fade rapidly when hitting the complexity wall of the business. In practice, low-code platforms are efficient to build applications in the context that has been anticipated by the platforms, or to build simple PoCs. However, as soon as one crosses the low-code platform frontier, it is becoming harder and harder to get things working. In the end, low-code platforms experts are needed to keep things going, often resulting in applications that are even more difficult to deploy, scale, and maintain.
The Core Problem with Traditional Development Approaches
The traditional client-server model has obvious benefits when building collaborative and multi-user applications. It consists of building a common domain model and implement it in a database. For instance, if we have a collaborative todo list application, we may have a “todo” table implementing the concept of a todo-list entry. Then, if we want our application to be multi-user and collaborative (which is the case of most useful apps for businesses of all sizes), we have to add the concept of a user and add a service layer to ensure the collaborative logic. For instance, we may want to add a feature to assign a todo to a given user. However, then comes the concept of a role and of an owner, since not everybody will be able to re-assign a todo item or delete it. Eventually the application service layer (implemented behind a REST API for instance) will contain a complex logic. This logic ensures that all the users will have access to the data they can see, and ensures that all the actions the users can do are actually permitted by the business rules. This business logic can become extremely complex when dealing with security issues and regulations such as GDPR (for instance).
The implications of such complexity is huge for the low-code approaches. It means that in the end, even when you use an efficient low-code tool to build your frontend, you still have to implement a complex business logic on the server side for your collaborative app. This implies complex workflows, complex business rules to check the access rights and authorisations, and so on. It means that you will need to deploy and maintain an API, a business layer in the application services, and a database at the very least to store all the data. And since this logic is not generic, but application-specific, it means that you need such a backend stack for all your applications. You may use a low-code tool to do it, but as the complexity grows and the need of scalability increases, a more traditional approach with a CI/CD pipeline will be needed, in order to keep up with the versions and evolutions of the APIs. All this meaning that the agility gained with the low-code tools is now lost and you need again a team of IT experts to ensure that your application meets the safety/security/scalability standards.
A Solution: the Local-First Software Paradigm
In their foundational paper, Martin Kelppman, Adam Wiggins, Peter Van Hardenberg, and Mark McGranaghan introduce a new paradigm for software development called the Local-First (LF) Software paradigm.
Martin Kleppmann, Adam Wiggins, Peter van Hardenberg, and Mark McGranaghan. Local-first software: you own your data, in spite of the cloud. 2019 ACM SIGPLAN International Symposium on New Ideas, New Paradigms, and Reflections on Programming and Software (Onward!), October 2019, pages 154–178. doi:10.1145/3359591.3359737
As its name says, the LF paradigm is about seing an application as a local application first. With the LF paradigm, each user will own his/her data, and this data may remain local (typically like a desktop application). Then we can use a synchronisation protocol to share the data among several devices. The user can still retain the ownership and privacy (since the data may be encrypted, even when using some cloud storage service). By essence, this way of doing things allows offline work and can improve the User eXperience, the same time it is reducing remote calls to servers and APIs over the internet.
Now comes the collaborative part. In order to make LF collaborative, the idea is to provide a native and generic protocol to allow a user to share its own data (or a copy of it) with other users. That way, multiple users can work on the same data and collaboration workflows can be implemented. However, on contrary to classical approaches, the user remains the owner of his/her data, because it is the user who decides what data should be shared and with whom it shall be shared (the same way you share a Google doc on a remote drive for instance).
Kelppmann et al. highlight seven characteristics of LF software. They don’t need to be all enforced.
- No spinners: your work at your fingertips – indeed, since no remote calls are necessary and no particular security checks need to be done (you own your data), the User eXperience can be improved, with much faster response times.
- Your work is not trapped on one device – nor on one server (the synchronisation protocol allows multiple devices to have a copy of the data, which also ensures better safety in case of a datacenter disaster and server loss).
- The network is optional – this means full offline work and potentially saving resources, as the network is energy-consuming.
- Seamless collaboration with your colleagues – It comes by design with the sharing protocol.
- The Long Now – your data will always remain on your local storage, so you don’t need to be afraid of your cloud providers anymore.
- Security and privacy by default – by design.
- You retain ultimate ownership and control – GDPR compliant.
Additionally, I will add a few crucial points:
- Complexity is drastically reduced – because you don’t need a specific API implementing complex data access policies and security (all your applications can rely on the same data sync and sharing protocol).
- Natural data partitioning – since each user shall own his/her data, all the users data is not mixed up in one unique database like with classical centralised approaches, which means that it opens doors for scalability.
- GreenIT friendly (if well used, of course) – you will save a specific backend stack for all your applications (including the associated CI/CD), and you will better distribute the resources across the devices and save a lot of remote calls to remote servers and APIs.
Local-First at Work with the dLite low-code platform
If I take again the todo list application example, an LF approach, would be the following:
- Each user has its own todo list, a todo list is a collection of objects
- Nobody besides the owner can access or modify the todo list (by design)
- A user can decide to share a list or an item with other users thanks to the sharing protocol (of couse, on the frontend side, the application may implement user-friendly actions to allow this with the appropriate UX).
- Other users will access the shared items and will be able to modify them and synchronise so that the owner may see the changes.
In dLite, I have implemented this kind of protocol for two example applications.
- A simple kid-reward application (where parents can share good points to kids when they behave). Check the project here.
- A collaborative absence management app, where a manager can accept or refuse the absence requests of a team, thus implementing a quite advanced workflow in a straightforward way. Check it out here.
A strong requirement for having it working is to have an authentication service (each user needs to be authenticated). So far I use the Google Authentication (OpenID connect) dLite plugin. However, any other source of authentication could be used.
Once the user is authenticated, dLite connects to the default data synchronisation and sharing service. Each dLite user has a free (limited) sync space on dLite.io to get started, however an organization may request an on-premise sync server. So, all the data, which is by default stored in the browser’s local storage is synchronised on the server with a generic protocol, which is controlled by the frontend.
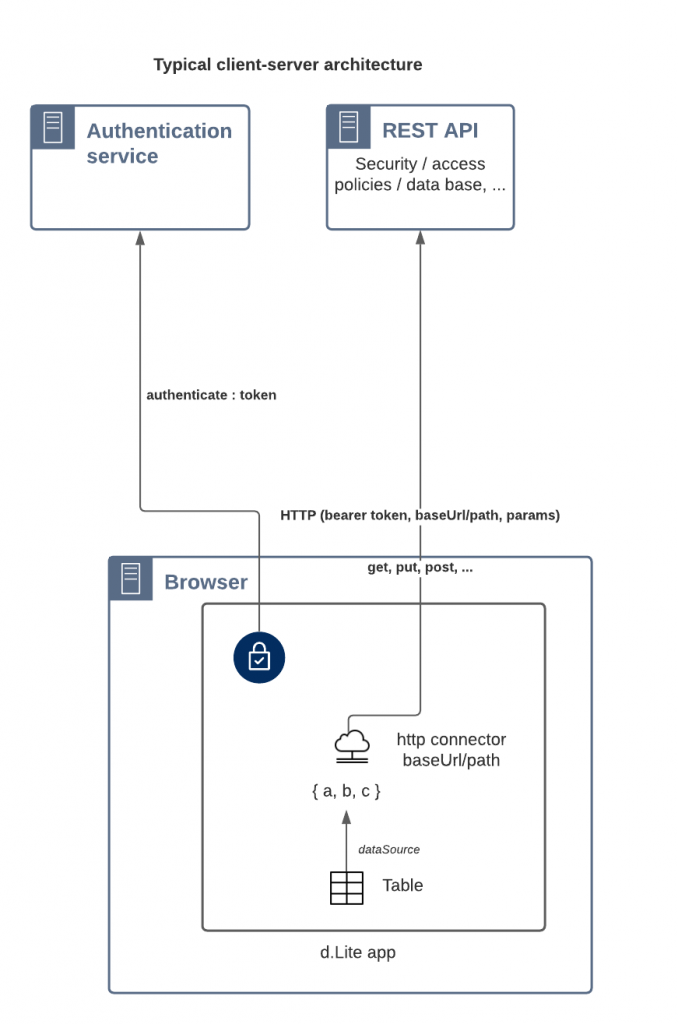
The following figure shows the architecture of a typical client-server application. The client uses a connector to a REST API. The main drawbacks of this architecture are the following:
- Need to implement / deploy and maintain a REST API
- All user data mixed within a database => complex access rules to be implemented
- Once the service is there, any evolution requires a new version of the API and data base evolution N apps => N APIs
On the other hand, one can see an LF architecture below. The application uses a local storage connector so that all the data can remain local. A synchronisation process (that requires authentication) synchronises the user’s data in its own space. It is built-in within the dLite low-code platform so that anyone can leverage the LF paradigm to build collaborative applications.
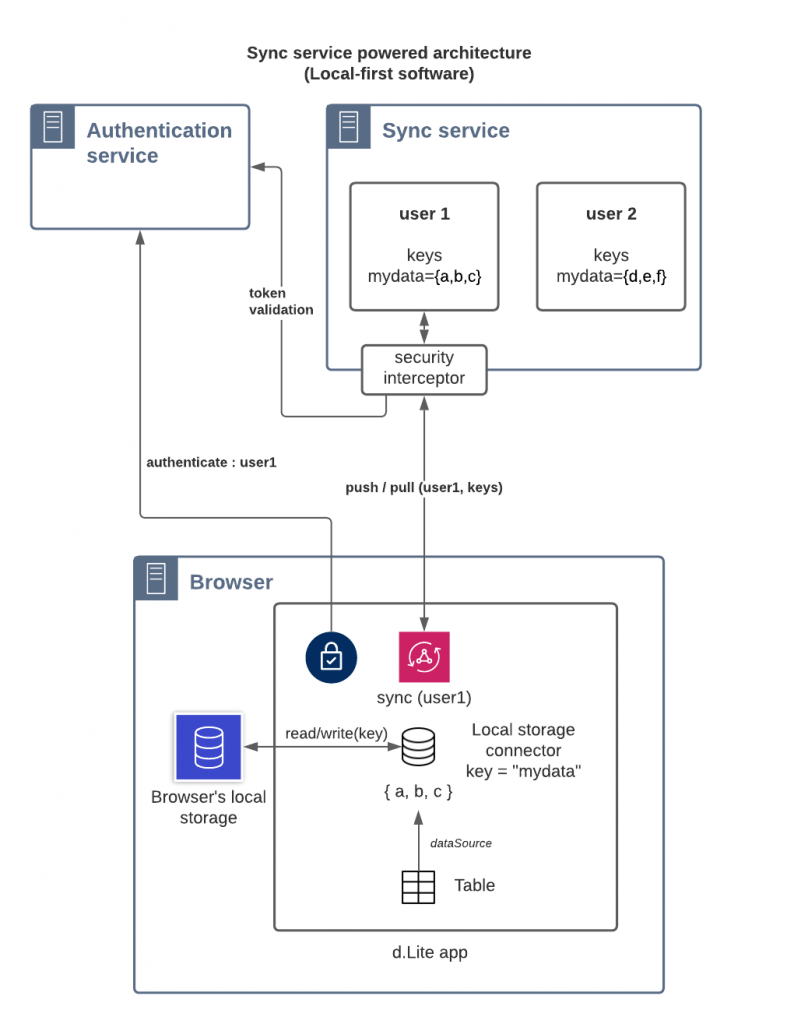
The advantages of such a LF architecture are the following:
- Each user owns his/her own data (secure and private by design)
- Generic protocol: no API to develop (N apps => 1 sync/share API)
- Easy evolution (personal data can change with the dLite application, shared data should avoid changes, except if all clients migrate at once)
- Offline work possible (WPA also), but optional (data may only remain server side)
- More efficient use of resources (less traffic, distributed over the terminals instead of one huge server)
- Scalability is possible with data partitioning (which is intuitive thanks to ownership)
Conclusion
In this white paper, I try to show that the Local-First paradigm is a solution to keep the low-code platforms efficient for collaborative applications. Without LF, the complexity can easily be out of reach and the benefits of Low Code can be lost, unfortunately.
I have already implemented prototypes (kids rewards and absence management) of such an approach with promising results, and currently starting developing real-world applications with Cinchéo’s partners. In the coming months, I will try to update you with these experiments, so keep in touch and don’t hesitate to reach out if you want to be part of the journey 😉
CI/CD is not anti-agile, it is one the tools that enables agility. It is mostly a fixed cost, but I see it as an investment since it allows you to iterate faster.
I It looks to me like clean architecture provides some answer to the complexity induced by access rights management. You usually have a domain layer which does not know anything about access rights : it describes the business domain (such as a todo list is a list of items, you can add or remove items and reorder them). And the business layer handle access rights and other business rules. And business rules are just as complex as the business requirements. As long as you users cannot share anything, it’s pretty simple : only the owner can see and edit the data.
I clearly see the benefits for applications where the data is personal and by definition owned by one user. But for fully collaborative workflows (any enterprise application basically : the data is owned by the company, not a single employee. And roles in the company are given access rights, not employees, so that for instance if the accountant changes, the new one automatically has access to accounting data and the previous one does not have access anymore), the data is more collectively owned by a group of people, so the whole concept of data ownership is different in this context I think (In the kids reward example, the data is owned by both parents). I’ll have to check the absence management app to see how you handled this.
P.S : you should choose an other subject than kid-reward, this so XIX-XXth century style education 😉
You are right about the company owning *most of* the data. However, that is not really a problem. What you need is some sort of admin user that represents the company. That user can share the appropriate data to the other users (sharing can be done automatically when a new user enter the system). Of course, you may share only fraction of the data (in read-only or read-write) depending on the user’s roles. These roles can be also owned by the admin. That way of doing things has the advantage to force you thinking about what is owned by the company (that heavily depends on the application), and what is owned by the users. In a way, it forces you to address GDPR better.
For the absence management application, I assumed that the operational data is decentralized and owned between the manager and the managees. So you will not find any data centralization or role reification here (roles are actually implicitly given by the app and available features). It is doable to have a centralized version, but it was not my purpose. Since then, I have implemented a muli-role collaborative app with a partner company with some global data control at the hand of the administrator (the roles) and of another administrator which owns application data. Note that the operational data can differ from the global data owned by the admins because the company sometimes don’t need to see all the operation detail of what happens during a workflow (sometime, an aggregated data can be sufficient). So, another advantage of this approach is to have you think about what data is important to keep (and eventually archive), and what data is only there for the operational workflows (for example saving a form content to work on it again later). Besides, the operational data is naturally partitioned in the user’s scope, which makes archiving and cleaning decisions easier. All this goes well with responsible software development.
About CI/CD, I don’t think that CI/CD is anti-agile. However, it is extremely powerful, and like all powerful tools, it consumes energy, which induces a Jevons paradox. All tools have to be carefully chosen depending on the context. But indeed, local-first should have CI/CD when CI/CD is required.